I tried to keep it simple, let me know if you have any suggestions for improvement:
www.strollswithmydog.com/photons-poisson-shot-noise/
Jack

I tried to keep it simple, let me know if you have any suggestions for improvement:
www.strollswithmydog.com/photons-poisson-shot-noise/
Jack

I gave it a quick look, and have two major remarks (and a few more minor ones, like you use the term variance a bit too loosely, while it should be reserved for the square of the standard deviation):
When you add the two standard deviations in quadratures, in other words, you add the two variances, which property do you use? If you have two independent noises added to each other, their variances add, indeed. This is not the case here, however. First, the standard view of noise is to have zero mean, and none of those two random variables has zero mean. This is not a big problem because one can adjust for it easily but it has to be done. Most importantly, you are not adding binomial noise to Poisson one. It is not like you have 100 photons in average, +/-10, and you randomize them additionally by adding binomial fluctuations with variance 100QE(1-QE) (and mean 100QE?). The effect of QE<1 is not additive noise; it is a composition of random variables in my understanding (like in conditional probability). In the end, your calculations get the right answer, and there might be a way to explain why that I do not see now, but the way it is presented is not right.
Also, you get a standard deviation corresponding to a Poisson process with mean s*QE. That, by itself, does not mean that the process is Poisson. It is just a happy coincidence. To show that the new process is Poisson, you need to verify its defining properties, and you actually did so in your posts here earlier. Or do the calculation I did.
Thanks JACS, much appreciated, I'll put some thought into how to explain it better without complicating things too much.
Jack
No, I'm not. 'Expected value' means exactly what it sounds like, the value that is expected. Expected value is P(x)*n. That's only the mean if you consider that the probability of each event is the same. For a photo communicating any image apart from a grey card that clearly is not the case.
No, it does not mean that. In our case, it is the mean of the process creating it with respect to the probability measure. This is reflected by the formula defining is a integral of x times dP(x), where the latter is the probability measure. We have to give it some catchy name, and we call it "expected value." We could have called it a "cow" but it would have been less intuitive.
Again, there is the expected value of the process and the mean of finitely many samples. Those are different animals. The latter converges to the former with infinitely many samples but for every finite number, it is only "close."
EDIT: Let me give an example: You roll a die, once at a time. The process gives you 6 possible outcomes with probability 1/6 each. The expected value is 3.5, which ironically never happens. It is the weighted average of all outcomes with weight 1/6, which happens to be the arithmetic mean as well. Now, you roll it 10 times. You are not going to get a mean 3.5 most likely. Roll it 100 times. You will get closer with high probability, roughly speaking, etc. The expected value of the process is still 3.5.

In another thread on this forum, I made a coarse demonstration of the random arrival times, but used block code instead of a graphic, so I was stuck with low resolution, which gives a general idea, but with unrealistic spacing that is more consistent than the real thing:
TIME->
Ideal: 0 1 2 3 4 5 6 7 8 9
Real-A: 0 1 2 3 4 5 6 7 8
Real-B: 0 1 2 3 4 5 6 7 8 9 10
Running some actual code in Processing, though, we get much more variety in spacing, which, in a car model, might indicate a lot of "tailgating":
size(500,200);
for(int x=0;x<width;x++)
{
if(random(1)<0.03) line(x,0,x,height);
}
But we're not talking about the process of rolling a die. We're talking about the process of photons being reflected off various objects and arriving at the sensor. The expected value of a spatial sequence of samples is certainly is not the mean.
It is always the mean with respect to the probability measure, just by definition.
For a Poisson distribution, the probability to have value k is 
Please provide this definition.
Perhaps one would expect a sequence of values from a sequence of samples ... 😉
...
Here: en.wikipedia.org/wiki/Expected_value#Arbitrary_real-valued_random_variables
As they say there: Despite the newly abstract situation, this definition is extremely similar in nature to the very simplest definition of expected values, given above, as certain weighted averages. This is because, in measure theory, the value of the Lebesgue integral of X is defined via weighted averages of approximations of X which take on finitely many values. Moreover, if given a random variable with finitely or countably many possible values, the Lebesgue theory of expectation is identical with the summation formulas given above. However, the Lebesgue theory clarifies the scope of the theory of probability density functions.
In particular, here: en.wikipedia.org/wiki/Expected_value#Random_variables_with_countably_many_outcomes
Informally, the expectation of a random variable with a countable set of possible outcomes is defined analogously as the weighted average of all possible outcomes, where the weights are given by the probabilities of realizing each given value.
See also the second paragraph on p.386 here: link.springer.com/content/pdf/10.1007/978-3-030-33143-6_12.pdf
Good one John. This is what I came up with for photons in 2D (it's a GIF, so click on it to see the simulation)
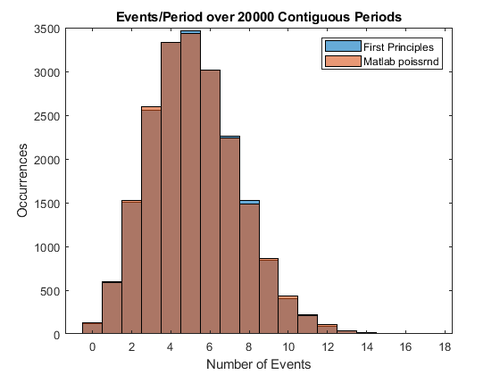
And this is the histogram for a constant mean rate of 5.2 random events per unit of time or space
generated with this self evident code in Matlab: 104,000 events over 20,000 slots
Full code for the figures above in the notes of the relative article.
Jack
I am not very good at reading pseudo codes or even actual ones. What is the code doing here? Throwing away integers in random, and then you count how many are left in an interval of length n, like in [1, n], [n+1,2n], etc.? If so, this is not Poisson.

It looks like he's doing 500 Bernoulli trials with p=0.03. So it's an approximation to Poisson. Seems good enough.
Maybe you would prefer something like:
double last_arrival_time = 0.0;
for( int i = 0; i < n_arrivals; ++i )
{
double wait = -log( 1.0 - random(1) ) / lambda; // Exponentially distributed, parameter lambda
last_arrival_time = last_arrival_time + wait;
arrival_time[i] = last_arrival_time;
}
// At this point, last_arrival_time has distribution Erlang(n_arrivals, lambda)
I can't see the definition that you were talking about there. When you say that something is true 'by definition' it means that the proposition you are making is contained within the definition. What you're saying is that 'expected value' means 'mean' because 'expected value' is defined as being the mean. None of these sources provide such a universal definition. There are definitions is specific cases.
Still this is precisely a semantic argument and has probably run its distance.
Is this supposed to result in a Poisson distribution John? If so I am having difficulty understanding how it would come about.
I guess that "is" was "in." The definition with the measure is the most general one, covering all of them. In any case, each one is a weighted average/mean.
It does not have to be an argument at all. No mathematician or statistician would object what I said. They may have different way of saying things, but they would not say that it is wrong.
The number of arrivals before time t (t >=0) has a Poisson (Should be de Moivre really, see Stigler's Law) distribution with mean lambda*t, where lambda is the expected number of arrivals per unit time.
The waiting time for an event in a (homogeneous) Poisson arrival process has an exponential distribution. Like the waiting time for a radioactive nucleus to decay, it doesn't matter when you start your clock, the distribution of waiting times, and the expected waiting time is always the same.
I wrote my pseudocode that way because John Sheehy posted some (pseudo?) code that drew lines in a way that was intended to (and does) approximate arrivals in a Poisson process.
The arrival_time[i] in my code says where to put the lines. To make my (pseudo) code give a similar distribution of lines to John Sheehy's code, use lambda = 1.0/0.03 - and keep going until last_arrival_time > 500 . Problem with my code is that, for any given number of arrivals, there's a finite probability of an even larger number of arrivals before t=500 . Also, how do you draw the lines when there are arrivals at t=453.1, t=453.2, and t=453.6 ?
The
double wait = -log( 1.0 - random(1) ) / lambda; // Exponentially distributed, parameter lambda
bit is just inverting the CDF of an exponential distribution.
Earlier,
The relationship between the exponential and Poisson distributions is quite fundamental. The exponential distribution gives the waiting time between events in a Poisson distribution.